隨著深度學習和人工智能領域取得突破性進展,以及無人配送車、無人出租車、無人巴士等智駕場景逐步落地深入,自動駕駛行業近年來取得了越來越多的關注和進步。然而,想要真正實現在道路上行駛,還需要解決眾多技術問題。
01

為了進一步提升小文件篩選與治理流程,焱融科技采用了增加虛擬子目錄的方式,雖然這種方式增加了一層目錄查詢的操作,但是其具備靈活性強的特點,可以將熱點分攤到集群中所有元數據節點。同時,這種解決方法還可以解決另一個問題——單目錄的文件數量問題,使單目錄實現支撐 20 億左右的文件數量,并且可以根據虛擬子目錄的數量靈活調整。整體結構如下圖所示:
·在客戶端緩存過程中,由內存緩存 + GPU 服務器本地 SSD 緩存組成;
通過焱融 YRCloudFile 所提供的方案,可實現在整個訓練中,數據集加載速度提升5倍的效果。
04
05
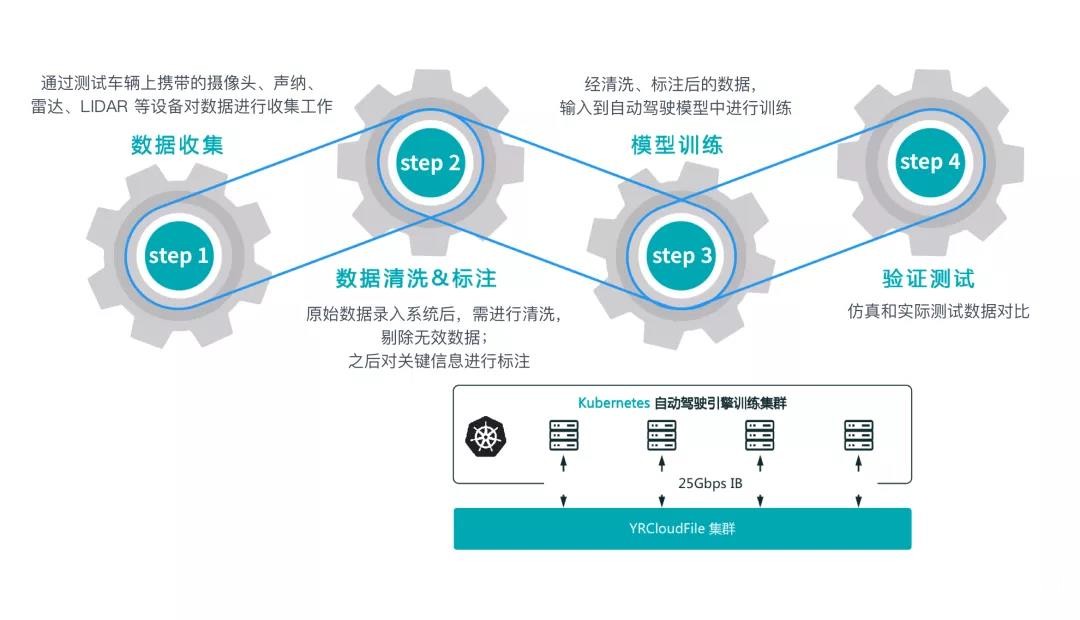
感知系統作為車輛路徑規劃的依據之一,需要通過“數據訓練”夯實基礎,以監督學習的方式,將數十 PB 的訓練數據提供給算法,通過其生成具有普適感知能力的模型,幫助自動駕駛車輛擁有更好地感知實際道路、車輛位置、障礙物信息等方面的能力,達到實時感知在途風險,作出具體行為決策的目的。
隨著越來越多的雷達、攝像頭等傳感器被部署在車輛里,各個環節的工作量與日俱增,尤其是高性能自動駕駛汽車對數據的存儲需求更是巨大,一天生成的數據量可達到 3-8 TB 左右。因此,如何高效、穩定地保證自動駕駛過程中收集到的大量數據,并快速形成自動駕駛的計算模型,成為了各大自動駕駛企業關注的首要問題。
本篇文章,焱融科技將基于國內某專注于研發和應用L4級自動駕駛技術,聚焦自動駕駛出行和自動駕駛同城貨運兩大場景的自動駕駛公司實際案例,分享 YRCloudFile 在自動駕駛訓練場景下針對 IO 模型、容器化部署、性能提升、智能分層方面的實踐經驗和啟發,希望能給相關從業者解決類似問題時提供一些參考和幫助。
海量數據,毫厘必爭
此前,國內某 L4 級自動駕駛公司主要采取的是開源的存儲解決方案,將 GPU 計算和存儲以融合的形式進行部署,但是隨著文件數量的上升,性能出現明顯下降,原有的存儲方式也逐漸開始影響訓練的效率。因此,他們開始考慮升級現有的存儲解決方案。
在升級過程中,該公司重點關注并解決以下問題:
·在日益劇增的海量數據場景下,如何提升設備性能,加快訓練進度;
·開源方案雖然具備解決海量文件的能力,但是隨著數據量的增多,如何保證產品穩定性,避免難以維護的問題;
·如何解決存算融合架構下,無法根據需求單獨擴容的問題;
·在數據經歷收集、清洗、訓練后,如何解決過程中所產生的冷數據的問題。
YRCloudFile 如何應對?
在了解該公司駕駛訓練場景以后,焱融科技針對其自動駕駛訓練數據集進行了一系列分析,并總結出其訓練數據具備以下特征:
·浩瀚數據文件,訓練數據集的文件數量在幾億至幾十億甚至上百億的規模;
·小文件難治理,大部分文件的大小在幾 KB 到幾 MB 之間,一些特征文件的大小更是只有幾十到幾百 Byte;
·讀多寫少,在數據寫入存儲后,根據訓練要求會進行多次讀取。
針對上述特征,焱融科技從元數據處理能力、目錄熱點、多級智能緩存、針對性調優再到智能分層,提供了一系列高性能、高可用、高擴展的存儲方案。
焱融 YRCloudFile 自動駕駛應用場景下的工作流程
01
元數據處理能力,處理海量數據文件的基石
在面臨海量文件時,由于 MDS 不能及時地響應讀寫請求,所以極易出現應有性能無法發揮的情況。如果想要突破存儲的瓶頸,主要解決方案是提升元數據的處理能力。
為此,焱融科技選擇通過可水平擴展設計的 MDS 架構,實現 MDS 集群化。這主要考慮到以下三方面:
·第一,MDS 集群化有利于緩解 CPU,降低內存壓力;
·第二,多個 MDS 有利于企業存儲更多元的數據信息;
·第三,在實現元數據處理能力水平擴展的同時,提升海量文件并發訪問的性能。
目前,焱融 YRCloudFile 主要采用靜態子樹 + 目錄Hash兩者結合的方式搭建可水平擴展設計的 MDS 架構,其主要包含三大要素:
·將根目錄固定在 MDS 節點;
·每一級目錄會根據 Entry name 進行 hash,再次選擇 MDS,以此保證橫向擴展的能力;
·在目錄下文件的元數據進行存放過程中,不再進行 hash,而是跟父目錄在同一個節點,以此保證一定程度的元數據本地性。
這種架構方式有兩種好處,首先是實現了元數據的分布存儲,通過擴展元數據節點,即可支持百億級別的文件數量;其次是在一定程度上,保證了元數據的檢索性能,減少在多個節點上進行元數據檢索和操作。
02
目錄熱點,解決熱點引發問題的關鍵
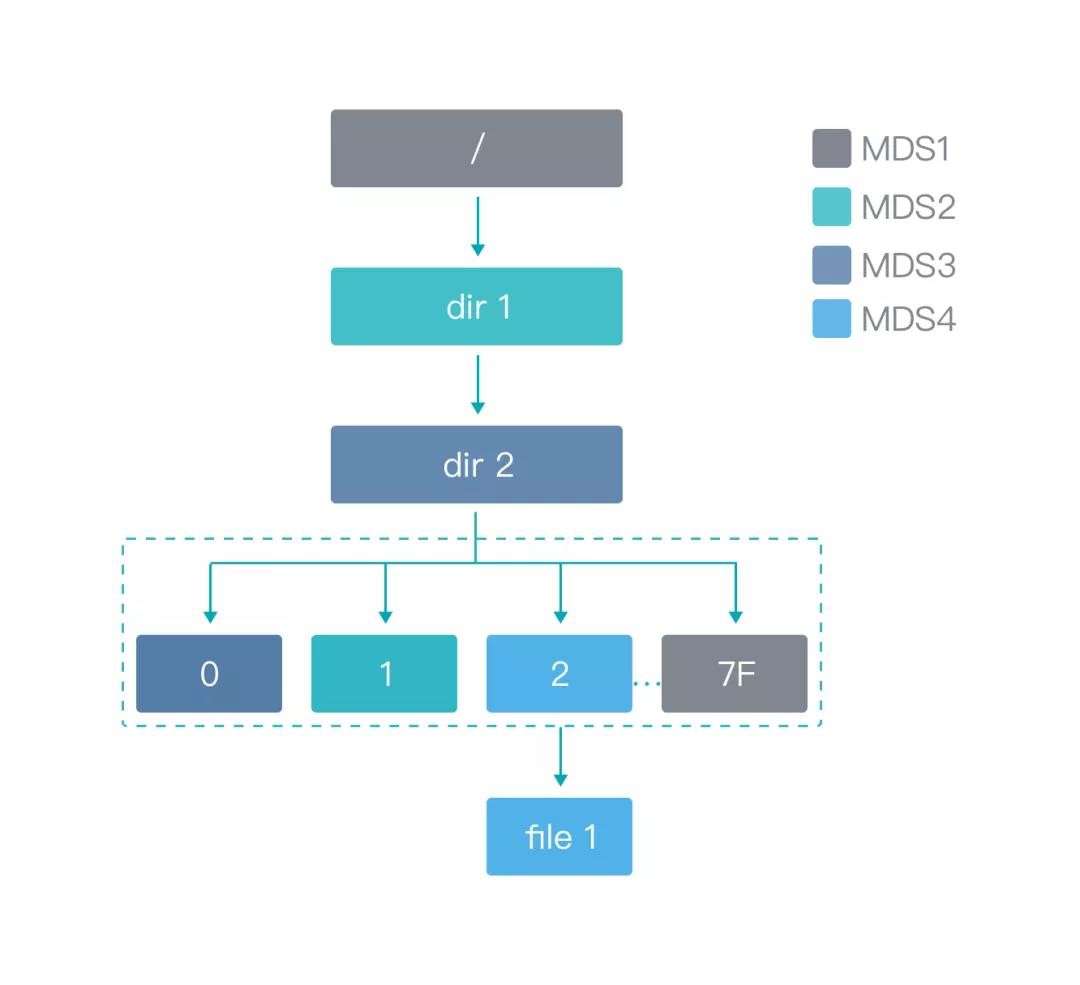
由于大數據集群的目錄以及文件數據數不勝數,所以在自動駕駛車輛訓練過程中,如果遇到多個計算節點需要同時讀取這批文件時,其所在的 MDS 節點就會變成一個熱點。整體結構如下圖所示:
為了進一步提升小文件篩選與治理流程,焱融科技采用了增加虛擬子目錄的方式,雖然這種方式增加了一層目錄查詢的操作,但是其具備靈活性強的特點,可以將熱點分攤到集群中所有元數據節點。同時,這種解決方法還可以解決另一個問題——單目錄的文件數量問題,使單目錄實現支撐 20 億左右的文件數量,并且可以根據虛擬子目錄的數量靈活調整。整體結構如下圖所示:
我們可以嘗試通過訪問/dir1/dir2/file1,來查看虛擬子目錄是如何實現的。在這里,我們假設,dir2 是開啟了 dirStripe 功能。主要訪問流程如下:
1、在 MDS1 上拿到根目錄的 inode 信息,查看沒有開啟 dirStripe
2、在 MDS1 上獲取 dir1 的 dentry 信息,找到所屬 owner(mds2)
3、在 MDS2 上拿到 dir1 的 inode 信息,查看沒有開啟 dirStripe
4、在 MDS2 上獲取 dir2 的 dentry 信息,找到所屬 owner(mds3)
5、在 MDS3 上拿到 dir2 的 inode 信息,查看開啟了 dirStripe
6、根據 file1 的 filename,hash 到虛擬目錄2上
7、在 MDS3 上獲取虛擬目錄2的 dentry 信息,找到所屬 owner (mds4)
8、在 MDS4 上拿到 file1 的 inode 信息,返回給客戶端
在整個模擬測試過程中,我們模擬了多個客戶端,并發訪問同一個目錄的場景。在完成以后,我們通過對比發現,目錄拆分后有10倍以上的性能提升。
03
多級智能緩存,提升整體性能的最佳實踐
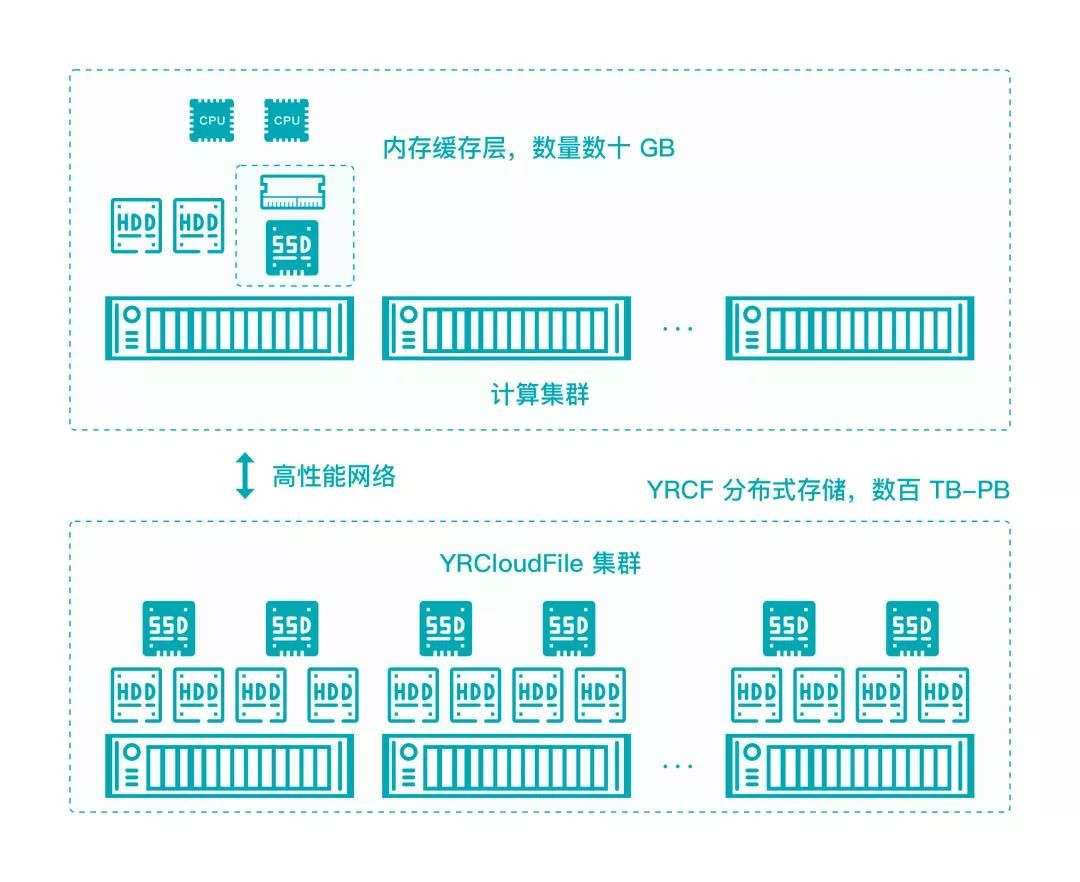
由于自動駕駛訓練數據有很多類型,不同數據信息存儲數據量不可估計,所以普通文件緩存容易出現只提供內存緩存,導致容量有限,通常一臺 GPU 服務器可用的內存緩存僅數十 GB;同時,也容易出現內存緩存 LRU 置換算法,epoch 緩存在每個 epoch 的命中率低的問題。
為了應對上述問題,焱融 YRCloudFile 客戶端采用能提升整體性能的多級智能緩存特點:
·在客戶端緩存過程中,由內存緩存 + GPU 服務器本地 SSD 緩存組成;
·可以指定緩存大小和位置;
·訓練程序先從客戶端內存緩存中加載,未命中則從客戶端服務器 SSD 加載,不命中最后從文件系統集群中加載;
·對訓練框架、應用程序完全透明。
YRCloudFile 客戶端多級智能緩存工作圖
通過焱融 YRCloudFile 所提供的方案,可實現在整個訓練中,數據集加載速度提升5倍的效果。
04
針對性調優,提升存儲性能的最優解
大多數存儲廠商在產品規劃、產品穩定性、技術服務等方面更為專業。在現場進行 POC 測試的過程中,焱融 YRCloudFile 進行了包括但不限于功能、性能、可靠性等方面的測試。從中我們發現,集群的性能已經超過原有存儲系統,但是沒有達到預期的數值。因此,我們可以通過對現場環境的分析,提出以下幾點優化措施:
1、增大節點上的 socks 數量,已獲得更大的連接數;
2、調整線程數 workers,以匹配訪問的數量;
3、調整 listeners 偵聽線程數;
4、調整輪詢策略,平衡響應速度和 CPU 資源。
經測試,通過針對性的調整后,YRCloudFile 可以將以上存儲參數的調整性能提升了 20%-30%。
05
智能分層,數據流動最佳決策
了解數據存儲的朋友都知道,訪問頻繁的數據為熱數據,訪問較少的數據為冷數據。然而,一旦冷數據過多,不僅會占用大量的存儲空間,而且存儲成本也隨之增加。
為此,焱融 YRCloudFile 專門提供了文件存儲系統目錄級的智能分層功能,通過高性能文件存儲+低成本對象存儲的組合,我們將有效實現熱數據依然為人工智能等新興業務提供高性能訪問的特性,而冷數據可以在用戶現有低成本的對象存儲中有效保存。目前,焱融 YRCloudFile 智能分層技術支持以下特性:
·根據不同目錄,可以定義不同的冷熱數據和數據流動策略;
·冷數據自動流動至低成本的對象存儲;
·提供標準的 POSIX 接口,數據在冷熱數據層之間流動對業務完全透明。
通過冷、熱數據智能分層的方式,可以滿足絕對大多數企業在自動駕駛訓練過程中,對于存儲高性能和數據長期保存的需求。
自動駕駛場景 YRCloudFile 無縫對接容器存儲
當前,為了提升自動駕駛訓練測試效率,大多數廠商以及 AI 應用會選擇在容器為應用運行載體的 Kubernetes 平臺上,運行 AI 訓練和推理任務。Kubernetes 在 AI 訓練方面主要有兩個優勢:
·首先,Kubernetes 支持 GPU 調度,可以減少協調 GPU 資源所需的人力。同時,它可以實現 GPU 資源的自動回收,做到資源的有效分配;
·其次,Kubernetes 支持多種負載的調度方式,適應不同的業務場景,作業與訓練任務兩者切合度非常高。
在自動駕駛訓練過程中,存儲系統對接容器場景常常遇到以下問題:
·采用 in-tree 類型的存儲代碼,如 CephFS、GlusterFS、NFS 等,使得 Kubernetes 和存儲廠商的代碼緊耦合;
·更改 in-tree 類型的存儲代碼,用戶必須更新 Kubernetes 組件,成本較高;
·in-tree 存儲代碼中的 BUG 會引發 Kubernetes 組件不穩定;
·in-tree 存儲插件享有與 Kubernetes 核心組件同等的特權,存在安全隱患;
·僅支持部分 AccessModes、PV 管理、故障等方面的特性。
焱融 YRCloudFile 從設計到實現,主要場景就是解決 Kubernetes 環境中,容器化應用對存儲的訪問需求。焱融 YRCloudFile 通過支持 CSI、FlexVolume 等插件,實現對 AI 場景容器持久化存儲的支持,并且根據客戶實踐應用,針對容器化場景的功能進行了優化:
·海量 PV 場景下,快速定位 PV 熱點,支持 RWO、RWX 等多種讀寫模式;
·實現 CSI 對 PV 的智能調度;
·依賴 PV 的 Pod 跨節點快速重建;
·呈現 Pod、PV、PVC 實時監控與關聯關系。
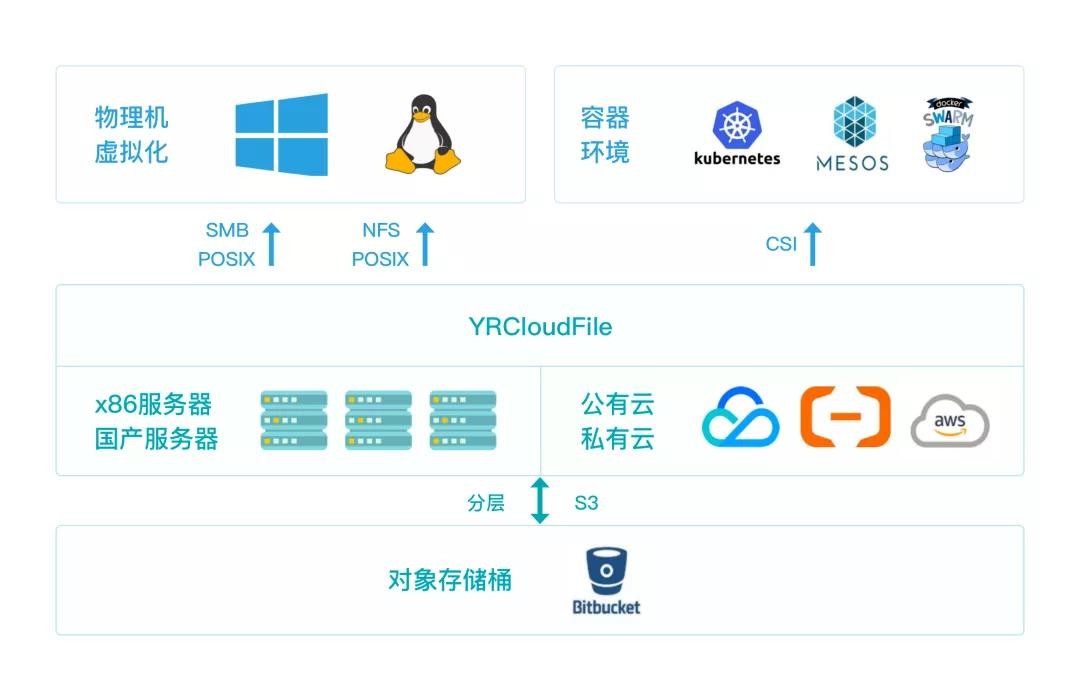
YRCloudFile 穿透自動駕駛存儲全鏈增長
YRCloudFile 高性能分布式文件存儲架構圖
通過焱融 YRCloudFile,該 L4 級自動駕駛公司突破了存儲性能的瓶頸,完美對接容器服務,完成數據跟隨服務。另外,通過快速定位 PV 熱點,該公司實現呈現 Pod、PV、PVC 實時監控與關聯關系等獨創性的管理功能,提升容器的管理效率。
當前,該 L4 級自動駕駛公司在焱融 YRCloudFile 高性能、高可用、易擴展的分布式存儲支撐平臺的幫助下,可以輕松應對海量小文件性能、容量的挑戰。同時,滿足了未來擴容需求。未來,該公司工作人員將極大減少在存儲系統管理、配置和排錯的時間,將更多的精力投入到訓練業務中。