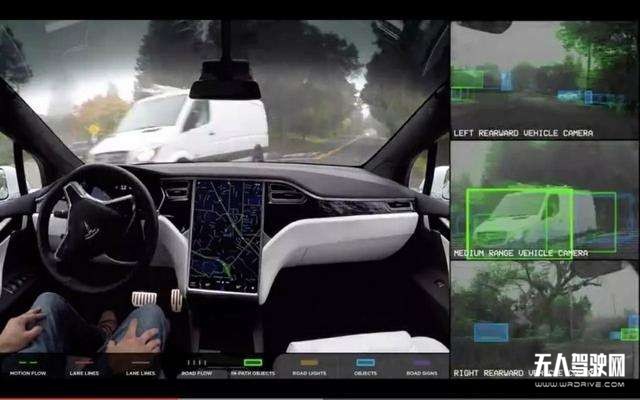
感知,包括了傳感器融合(整合多傳感器的數據)、物體檢測(發現障礙物)、物體分類(障礙物是不是行人),物體分割(行人位于道路右側還是左側)和障礙物跟蹤(行人在向哪個方向移動)等。
感知,是自動駕駛的前提,沒有精確的感知,自動駕駛就是一場災難!要做到精確的感知,必須采用多種探測技術,因為目前全世界還沒有一種探測技術能適應所有場景。
常見的感知傳感器主要有:視覺類成像傳感器(包括單目/雙目立體視覺、全景視覺、紅外相機等)和雷達類測距傳感器(包括激光雷達、毫米波雷達、超聲波雷達等)。
在光照良好的條件下,可見光視覺類傳感器就像人類的眼睛,可以提供最全面最準確的環境信息,但是在黑夜、雨霧雪等惡劣環境下,它們就無能為力了。紅外傳感器是近些年才被人們所重視的,能在任何環境或天氣條件下較準確地識別到生物,但是對徑向運動的辨別能力很差,沒有角度測量能力,不能完成靜止測距。
雷達類傳感器一般不受天氣或光照影響,但是它們不能精確地確定物體的大小和形狀,只能確定在距離多遠的地方有物體存在;有的雷達技術對部分材料敏感、對部分材料不敏感,可能會造成誤判。
激光雷達傳感器也是近些年比較火的技術,與其他的雷達類傳感器不同,它綜合了視覺傳感器和雷達傳感器的優點:能成像能測距、不受光照影響,但是也有缺點:成本很高、會受雨霧灰塵等環境因素影響。
前面說的這些感知技術,都是從車輛自身的角度來說的,是汽車采集環境數據的第一來源,但僅靠這些手段去實現高級別的自動駕駛還是不夠的。我們在ITA視角第三期文章《車聯網與5G和自動駕駛》里講過,借助于車聯網的V2X通信,汽車可以從周邊車輛、道路、基礎設施等獲取到更多信息,大大增強汽車對周圍環境的感知。通過這種方式,可以突破單車感知的局限性,降低單車傳感器的成本,擴大單車感知的范圍。
綜上所述,汽車會通過自身安裝的多個攝像頭、多個雷達等傳感器實時采集環境數據,也會通過V2X通信技術從周邊車輛等獲取環境數據,那么,這么多數據應該怎么處理呢?
首先,一個基本原則是,以汽車自身傳感器采集到的數據為主,從周邊車輛等獲取到的數據為輔。因為,沒有人愿意把自己的安危交給他人決定,萬一周邊車輛等傳遞過來的數據是過期失效、甚至是惡意篡改的呢?
其次,汽車自身采集的數據也有很多種,有的是2D圖像數據,有的是3D激光點云數據,還有的是距離數據等。而且,不同種類的數據還會有多個來源,有的是車前方的,有的是車后方的,還有的是車兩側的。所有這些數據,有兩種處理方案:集中式處理方案和分布式處理方案。所謂集中式處理,就是傳感器只管產生數據,把產生的大量數據通過高帶寬的總線傳輸到高性能的中央處理器,由中央處理器進行大量的運算處理;所謂分布式處理,就是傳感器不僅產生數據,還要把產生的數據先進行預處理,然后再把處理后的少量數據通過總線傳輸到中央處理器,中央處理器只需要進行融合等少量的運算處理。
不管哪種方案,所有傳感器的數據都需要進行深度融合,合成為包含多個角度、距離、維度的全方位的環境數據,然后在此合成數據基礎之上再進行識別和處理,進行物體檢測、物體分類,物體分割和障礙物跟蹤等。
除了需要感知,汽車還需要定位和高精度地圖。有了定位和地圖,才能知道我在哪里、目的地在哪里、怎么去目的地。地圖好說,有專業的公司專門負責制作和維護,那么定位怎么弄呢?一般有三種方法:
1、基于地標定位。根據視覺傳感器或者激光雷達傳感器采集到的圖像,與數據庫中的特征進行匹配,確定車輛的位置。
2、基于信號定位。車輛安裝GPS和/或北斗,獲取衛星定位信號;還可以通過4G/5G的蜂窩通信系統基站定位。
3、基于慣性定位。首先知道車輛的起始位置,然后根據慣性傳感器來的數據計算車輛當前的位置和方向,本質上就是在初始位置上不斷累加位移矢量來計算當前位置。
通常情況下,使用最多的定位方法,是2、3兩種方法的結合,即衛星定位+慣性導航。而在自動駕駛中,為了保證高準確度,往往采用1、2、3三種方法結合,即先使用衛星定位+慣性導航先判斷出大概位置,再使用高精度地圖與感知系統獲取到的圖像進行對比計算,確定出更精確的位置。
最后,有了對當前周邊環境的感知,有了定位和地圖,那么就可以通過大量復雜的計算,制定出車輛的運動軌跡和行為動作,也就是規劃與決策。為了保證自動駕駛的安全性和舒適性,對算法就提出了很高的要求:速度要快,要能對動態的大量數據快速計算出結果;結果要合理,稍有差錯可能就造成嚴重的后果;算法要智能,能自動學習,能正確處理各種未知的突發情況。
在以前,傳統的編程模式是窮舉式的,典型的就是if...else if...else這種結構,把所有已知情形都列舉出來并一一給出處理辦法,然后其他所有未知的都歸并到else這一個地方給出一個籠統的處理辦法。以這種思路寫出的程序如果用于自動駕駛,可能會出現什么樣的結果?大家自己可以想象。
隨著技術的發展,神經網絡理論逐漸成熟,科學家基于對人類大腦神經細胞、學習和條件反射的觀察和研究,建立并完善了深度學習的算法模型。與以前算法最大的不同就是,它是基于大量數據訓練逐步自己完善自己的,而不是由開發者事先確定好的。甚至模型中的很多參數,開發者自己都不能解釋為什么應該是這個值而不是其他值。
很多人在上大學時可能都干過這樣的事:做實驗,自己的實驗沒做好,結果不理想,于是從別的同學那里抄來結果,然后開始修改自己的實驗中間過程數據,讓數據能跟結果看起來吻合。深度學習算法本質上也是這樣做的:原始輸入數據和對應的最終結果都有了,算法開始自己拼湊公式中的參數,以使能根據輸入數據計算出相同的結果;然后換一批輸入數據重復相同的過程,拼湊出的參數既要保證本次計算能得出正確的結果,還要保證以前的數據也還是能得出正確的結果;重復這樣的過程,直到所有數據都訓練完,這樣最終拼湊出的參數模型,能保證所有已知數據都能計算出相應的正確結果。樣本數據越多,拼湊出的參數模型越能接近反映事物的本質。
實踐已經證明,這種解決問題的思路,要比從探究事物本質原理的角度建模寫算法要好,簡單、粗暴、有普適性。但是,畢竟是拼湊出來的,只能是盡可能地接近事物的本質,而不能保證100%就是事物的本質。
當前自動駕駛大部分是在L3級別的,叫有條件自動化,對方向盤和加減速中的多項操作提供駕駛支援,其他的駕駛操作由人類駕駛者完成。
L4級別是高度自動化,由無人駕駛系統完成全時駕駛操作,根據系統請求,人類駕駛者不一定需要對所有的系統請求做出應答,限定道路和環境條件,這是后面幾年人們的研發重點。
L5級別是完全自動化,允許車內所有乘員從事其他活動,無需對車輛進行監控。這是人們追求的目標,什么時候能實現?也許十年,也許二十年。但真到了L5普及的那一天,你敢用嗎?我覺得汽車的安全防護技術要有重大突破,即使自動駕駛決策失誤,也不能造成非常嚴重的后果,這樣人們才能安心地將自己的安危完全托付給汽車。